

Overview #
I built an autonomy stack for a rover-mounted robotic arm with one clear target: make sim-trained policies that can survive contact with real hardware.
Workstreams (one project):
- Windows Docker
- SB3 PPO and SAC
- Imitation Learning trial
- Starting RKLB
- RLKit trial and rl_sar trial
- Alpha and Omega
What I Built #
- A Windows + WSL2 Docker workflow for reproducible sim + training.
- SB3 PPO/SAC baselines for early policy experiments.
- An imitation-learning bootstrap from teleop demonstrations.
- RKLB as a cleaner framework extraction with the Omega decider.
- RLKit trials plus
rl_sarruntime integration work. - Alpha + Omega: the integrated navigation + press policy flow.
Windows Docker #
This exists to kill “works on my machine” problems. I wired the stack to run cleanly under Windows + WSL2 with a Docker-first workflow so new contributors can get to a running simulator without weeks of setup pain. The goal is a reliable, documented path from fresh machine to a working training run.
SB3 PPO and SAC #
This is the baseline RL track. I used SB3 PPO and SAC to build early policies, validate reward shaping, and get clean training/eval loops before moving to the more custom RLKit stack. It is intentionally practical: quick iteration, straightforward checkpoints, and easy comparison between runs.
Imitation Learning Trial #
Imitation learning is the bootstrap. I collected teleop demonstrations and trained a behavior-cloned policy to give RL a reasonable starting point for contact-rich manipulation. The current dataset includes a real teleop capture (teleop_20260302_014016.parquet) with 2,850 rows.
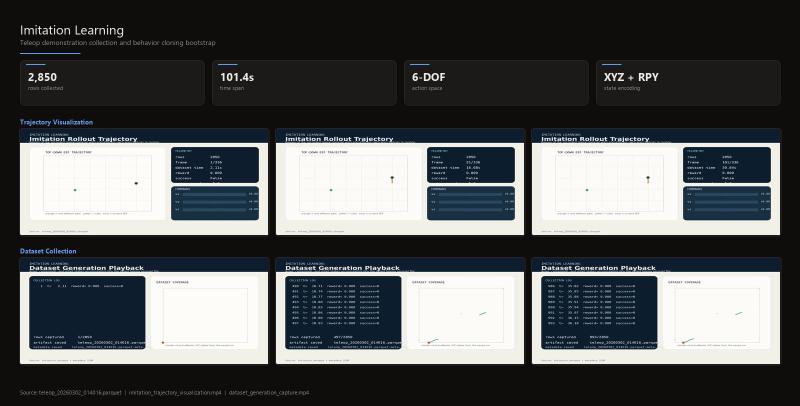
Starting RKLB #
RKLB is the framework extraction. It pulls the Omega decider state machine and backend abstraction into a cleaner, reusable package so the decision logic is separate from the low-level control plumbing. This is early-stage but already useful as a stable base for integrating Alpha/Omega style policies.
RLKit Trial and rl_sar Trial #
This is the exploratory branch: custom reach/keypad environments and RLKit training in rover2026_rlkit, plus rl_sar used as a runtime/deployment layer rather than the primary trainer. RLKit is where the stronger simulator integration lives today; rl_sar is about making those policies deployable in a rover stack.
Alpha and Omega #
Alpha + Omega is the integrated system that makes the behavior feel intelligent. Alpha handles navigation to the correct key. Omega executes the press with stabilized end-effector control. The split keeps the system understandable and makes failures diagnosable.

Current Status #
- Working in simulation with growing policy reliability.
- Hardware validation is the next checkpoint once the simulator policies are consistent enough.
- Main gaps are robustness across varied starting poses and contact sensitivity during the press.
- This project targeted the URC task, but we didn’t make it into the competition. I may update this page later with a working version.
Stack #
- Python
- ROS2
- MuJoCo
- Stable-Baselines3 (PPO, SAC)
- RLKit (trial branch)
- rl_sar (runtime/deployment layer)
- PyTorch
- Docker + WSL2


